By: Samuel Naffziger, SVP and Corporate Fellow, AMD

At a Glance:
- AMD has exceeded its 30x25 goal, achieving a 38x increase in node-level energy efficiency for AI-training and HPC, which equates to a 97% reduction in energy for the same performance compared to systems from just five years ago.
- AMD has set a new 2030 goal to deliver a 20x increase in rack-scale energy efficiency from a 2024 base year, enabling a typical AI model that today requires more than 275 racks to be trained in under one rack by 2030, using 95% less electricity.
- Combined with software and algorithmic advances, the new goal could enable up to a 100x improvement in overall energy efficiency
At AMD, energy efficiency has long been a guiding core design principle aligned to our roadmap and product strategy. For more than a decade, we’ve set public, time-bound goals to dramatically increase the energy efficiency of our products and have consistently met and exceeded those targets. Today, I’m proud to share that we’ve done it again, and we’re setting the next five-year vision for energy efficient design.
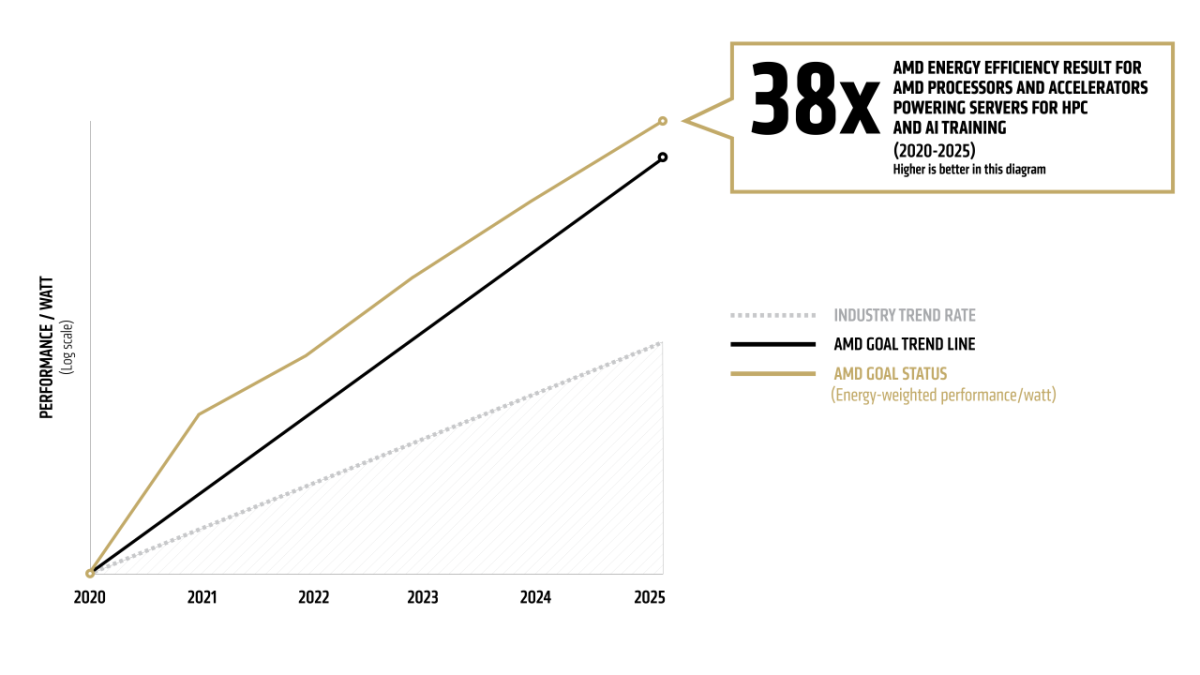
Today at Advancing AI, we announced that AMD has surpassed our 30x25 goal, which we set in 2021 to improve the energy efficiency of AI-training and high-performance computing (HPC) nodes by 30x from 2020 to 2025.1 This was an ambitious goal, and we’re proud to have exceeded it, but we’re not stopping here.
As AI continues to scale, and as we move toward true end-to-end design of full AI systems, it’s more important than ever for us to continue our leadership in energy- efficient design work. That’s why today, we’re also setting our sights on a bold new target: a 20x improvement in rack-scale energy efficiency for AI training and inference by 2030, from a 2024 base year.2
Building on a Decade of Leadership
This marks the third major milestone in a multi-decade effort to advance efficiency across our computing platforms. In 2020, we exceeded our 25x20 goal by improving the energy efficiency of AMD mobile processors 25-fold in just six years.3 The 30x25 goal built on that momentum, targeting AI and HPC workloads in accelerated nodes. And now, the 20x by 2030 rack-scale goal reflects the next frontier, not just focused on chips, but smarter and more efficient systems, from silicon to full rack integration to address data center level power requirements.
Surpassing 30x25
Our 30x25 goal was rooted in a clear benchmark, to improve the energy efficiency of our accelerated compute nodes by 30x compared to a 2020 base year. This goal represented more than a 2.5x acceleration over industry trends from the previous five years (2015-2020). As of mid-2025, we’ve gone beyond that, achieving a 38x gain over the base system using a current configuration of four AMD Instinct™ MI355X GPUs and one AMD EPYC™ 5th Gen CPU.4 That equates to a 97% reduction in energy for the same performance compared to systems from just five years ago.
We achieved this through deep architectural innovations, aggressive optimization of performance-per-watt, and relentless engineering across our CPU and GPU product lines.
A New Goal for the AI Era
As workloads scale and demand continues to rise, node-level efficiency gains won't keep pace. The most significant efficiency impact can be realized at the system level, where our 2030 goal is focused.
We believe we can achieve 20x increase in rack-scale energy efficiency for AI training and inference from 2024 by 2030, which AMD estimates exceeds the industry improvement trend from 2018 to 2025 by almost 3x. This reflects performance-per-watt improvements across the entire rack, including CPUs, GPUs, memory, networking, storage and hardware-software co-design, based on our latest designs and roadmap projections. This shift from node to rack is made possible by our rapidly evolving end-to-end AI strategy and is key to scaling datacenter AI in a more sustainable way.
What This Means in Practice
A 20x rack-scale efficiency improvement at nearly 3x the prior industry rate has major implications. Using training for a typical AI model in 2025 as a benchmark, the gains could enable:5
- Rack consolidation from more than 275 racks to <1 fully utilized rack
- More than a 95% reduction in operational electricity use
- Carbon emission reduction from approximately 3,000 to 100 metric tCO2 for model training
These projections are based on AMD silicon and system design roadmap and a measurement methodology validated by energy-efficiency expert Dr. Jonathan Koomey.
“By grounding the 2030 target in system-level metrics and transparent methodology, AMD is raising the bar for the industry,” Dr. Koomey said. “The target gains in rack-scale efficiency will enable others across the ecosystem, from model developers to cloud providers, to scale AI compute more sustainably and cost-effectively.”
Looking Beyond Hardware
Our 20x goal reflects what we control directly: hardware and system-level design. But we know that even greater delivered AI model efficiency gains will be possible, of up to 5x over the goal period, as software developers discover smarter algorithms and continue innovating with lower-precision approaches at current rates. When those factors are included, overall energy efficiency for training a typical AI model could improve by as much as 100x by 2030.6
While AMD is not claiming that full multiplier in our own goal, we’re proud to provide the hardware foundation that enables it — and to support the open ecosystem and developer community working to unlock those gains. Whether through open standards, our open software approach with AMD ROCm™, or our close collaboration with our partners, AMD remains committed to helping innovators everywhere scale AI more efficiently.
What Comes Next
As we close one chapter with 30x25 and open the next with this new rack-scale goal, we remain committed to transparency, accountability, and measurable progress. This approach sets AMD apart and is necessary as we advance how the industry approaches efficiency as demand and deployment of AI continues to expand.
We're excited to keep pushing the limits, not just of performance, but also what’s possible when efficiency leads the way. As the goal progresses, we will continue to share updates on our progress and the effects these gains are enabling across the ecosystem.
Footnotes
- Includes high-performance CPU and GPU accelerators used for AI training and High-Performance Computing in a 4-Accelerator, CPU hosted configuration. Goal calculations are based on performance scores as measured by standard performance metrics (HPC: Linpack DGEMM kernel FLOPS with 4k matrix size; AI training: lower precision training-focused floating-point math GEMM kernels operating on 4k matrices) divided by the rated power consumption of a representative accelerated compute node including the CPU host + memory, and 4 GPU accelerators.
- AMD based advanced racks for AI training/inference in each year (2024 to 2030) based on AMD roadmaps, also examining historical trends to inform rack design choices and technology improvements to align projected goals and historical trends. The 2024 rack is based on the MI300X node, which is comparable to the Nvidia H100 and reflects current common practice in AI deployments in 2024/2025 timeframe. The 2030 rack is based on an AMD system and silicon design expectations for that time frame. In each case, AMD specified components like GPUs, CPUs, DRAM, storage, cooling, and communications, tracking component and defined rack characteristics for power and performance. Calculations do not include power used for cooling air or water supply outside the racks but do include power for fans and pumps internal to the racks.Performance improvements are estimated based on progress in compute output (delivered, sustained, not peak FLOPS), memory (HBM) bandwidth, and network (scale-up) bandwidth, expressed as indices and weighted by the following factors for training and inference.
| FLOPS | HBM BW | Scale-up BW | |
| Training | 70.0% | 10.0% | 20.0% |
| Inference | 45.0% | 32.5% | 22.5% |
- Performance and power use per rack together imply trends in performance per watt over time for training and inference, then indices for progress in training and inference are weighted 50:50 to get the final estimate of AMD projected progress by 2030 (20x). The performance number assumes continued AI model progress in exploiting lower precision math formats for both training and inference which results in both an increase in effective FLOPS and a reduction in required bandwidth per FLOP.
- https://www.amd.com/en/newsroom/press-releases/2020-6-25-amd-exceeds-six-year-goal-to-deliver-unprecedented.html
- EPYC-030a: Calculation includes 1) base case kWhr use projections in 2025 conducted with Koomey Analytics based on available research and data that includes segment specific projected 2025 deployment volumes and data center power utilization effectiveness (PUE) including GPU HPC and machine learning (ML) installations and 2) AMD CPU and GPU node power consumptions incorporating segment-specific utilization (active vs. idle) percentages and multiplied by PUE to determine actual total energy use for calculation of the performance per Watt. 38x is calculated using the following formula: (base case HPC node kWhr use projection in 2025 * AMD 2025 perf/Watt improvement using DGEMM and TEC +Base case ML node kWhr use projection in 2025 *AMD 2025 perf/Watt improvement using ML math and TEC) /(Base case projected kWhr usage in 2025). For more information, https://www.amd.com/en/corporate/corporate-responsibility/data-center-sustainability.html.
- AMD estimated the number of racks to train a typical notable AI model based on EPOCH AI data (https://epoch.ai). For this calculation we assume, based on these data, that a typical model takes 1025 floating point operations to train (based on the median of 2025 data), and that this training takes place over 1 month. FLOPs needed = 10^25 FLOPs/(seconds/month)/Model FLOPs utilization (MFU) = 10^25/(2.6298*10^6)/0.6. Racks = FLOPs needed/(FLOPS/rack in 2024 and 2030). The compute performance estimates from the AMD roadmap suggests that approximately 276 racks would be needed in 2025 to train a typical model over one month using the MI300X product (assuming 22.656 PFLOPS/rack with 60% MFU) and <1 fully utilized rack would be needed to train the same model in 2030 using a rack configuration based on an AMD roadmap projection. These calculations imply a >276-fold reduction in the number of racks to train the same model over this six-year period. Electricity use for a MI300X system to completely train a defined 2025 AI model using a 2024 rack is calculated at ~7GWh, whereas the future 2030 AMD system could train the same model using ~350 MWh, a 95% reduction. AMD then applied carbon intensities per kWh from the International Energy Agency World Energy Outlook 2024 [https://www.iea.org/reports/world-energy-outlook-2024]. IEA’s stated policy case gives carbon intensities for 2023 and 2030. We determined the average annual change in intensity from 2023 to 2030 and applied that to the 2023 intensity to get 2024 intensity (434 CO2 g/kWh) versus the 2030 intensity (312 CO2 g/kWh). Emissions for the 2024 baseline scenario of 7 GWh x 434 CO2 g/kWh equates to approximately 3000 metric tC02, versus the future 2030 scenario of 350 MWh x 312 CO2 g/kWh equates to around 100 metric tCO2.
- Regression analysis of achieved accuracy/parameter across a selection of model benchmarks, such as MMLU, HellaSwag, and ARC Challenge, show that improving efficiency of ML model architectures through novel algorithmic techniques, such as Mixture of Experts and State Space Models for example, can improve their efficiency by roughly 5x during the goal period. Similar numbers are quoted in Patterson, D., J. Gonzalez, U. Hölzle, Q. Le, C. Liang, L. M. Munguia, D. Rothchild, D. R. So, M. Texier, and J. Dean. 2022. "The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink." Computer. vol. 55, no. 7. pp. 18-28.” Therefore, assuming innovation continues at the current pace, a 20x hardware and system design goal amplified by a 5x software and algorithm advancements can lead to a 100x total gain by 2030.
