By Derek Slater
Precision medicine is an emerging approach to treating complex diseases like cancer that lets doctors customize care based on a patient’s genetics, body type, and environment, and not just his symptoms.
It’s made possible by a confluence of technology trends: Doctors, hospitals and researchers capture more health data every year; computers have become more powerful, allowing them to keep up with growing data volumes; advances in analytics technology let medical professionals sift through all that data to identify patterns.
The problem is memory. Computers, even the most sophisticated ones, don’t have enough of it to perform these calculations efficiently.
“The practical tradeoffs of memory speed, cost and capacity have always been a limitation of the conventional architecture,” says Kirk Bresniker, an HPE fellow and chief architect at Hewlett Packard Labs. “Every other year, we double the amount of data that was previously created. But how do you turn that into action? We’re faced with this great opportunity, but can’t use our existing technologies to get there.”
Bresniker and his colleagues at Hewlett Packard Labs believe computing needs a fundamentally new architecture. So they’re developing a so-called Memory-Driven Computer that puts a nearly limitless pool of memory at the core of the system.
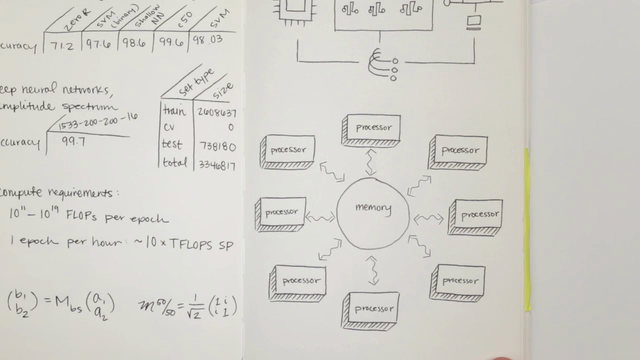
Today’s computers all use a basic architecture pioneered more than 60 years ago. A processor computes using data in memory. That memory is quick to access and very close to the processor. However, it’s also limited in size. So when the processor is ready for more data, it fetches it from a larger, slower storage system, and swaps the new data into memory to continue calculating.
As processing power has increased, the number of calculations a computer can perform at once has grown exponentially. But memory has become a bottleneck. Today’s preferred memory technology, DRAM, is expensive, and difficult to scale up to the level of a hundred terabytes and beyond, which is necessary for new uses like precision medicine.
The result is that, when they’re working on large, complex problems, computers can only look at one segment of that problem at a time. They run calculations on these segments independently and then assemble a complete answer. Parallel processing can help by breaking up problems to run across multiple processors at the same time. But the processors have to coordinate their access to memory, creating overhead that slows down the work.
For most day-to-day use, the performance lag isn’t noticeable and is more than made up for by the increased processing speed. Still, taking on data-intensive tasks like precision medicine, detecting financial fraud, or responding to a major transportation system outage is like trying to determine what’s pictured on a jigsaw puzzle by looking at the pieces one at a time. It’s slow to the point of impracticality.
Adding to the challenge, the steady, reliable growth of processing power described by Moore’s Law is coming to an end. Transistors can’t get much smaller than they already are using current materials.
“We’re all intrigued by the potential of data to change our lives, but just as we’re ready to take advantage of it, the technologies that got us this far are petering out,” says Bresniker.
Today’s ambitious data problems demand a different computing architecture altogether.
“What limits me is the amount of that data I can put in memory at one time, to analyze and run algorithms against,” says David Bader, chair of the School of Computational Science and Engineering at Georgia Institute of Technology.
Bader studies massive-scale analytics problems in fields such as computational biology and genomics. Large memory systems, he says, will “help me make the best decisions, even in situations where new data is streaming at me continuously.”
A key feature of the new architecture is direct photonic interconnections between each block of memory. By contrast, conventional memory blocks are connected by grids of copper wire that transmit data in the form of electrons. Fetching data from some blocks takes longer than others.
The new Labs approach replaces block-by-block data transmission with a much faster system based on direct fiber connections from every memory block to every other block. Data travels over this fiber in the form of photons—light—rather than electrons.
Now the processor can access data anywhere in memory at effectively the same speed, which allows the system to perform calculations far more rapidly. Another benefit: Many specialized processors can be brought to bear on individual computing tasks, all of them accessing the same shared pool of data.
Labs researchers still have some obstacles to overcome. To be practical at scale, Memory-Driven systems need to use non-volatile memory that retains information even when the machine is powered down. Right now, non-volatile memory is much harder to manufacture than DRAM at production scale.
While Labs researchers continue to develop the underlying technologies, they are using simulators based on today’s equipment to demonstrate the kinds of problems Memory-Driven Computing can solve. Here are four applications that show the transformational power of this new approach.
Smart cities
Cities are complex ecosystems. Something as simple as repairing a pothole can cause a chain reaction of events: Someone schedules work crews and allocates materials; the repair might impact a sewer line or privately owned utility; and it might require temporarily changing traffic signals, demanding attention from crews in other city departments.
“I can try to schedule the work to minimize disruption, but I’m just guessing about some of the effects,” says Sharad Singhal, director of software and applications for HPE’s Machine project.
Problems like this one, with many interconnected entities affecting each other in a variety of relationships, are known as graph analytics problems. In computer science lingo, each entity is a node, while the relationships between them are called edges.
Graph analytics problems aren’t limited to smart cities. Social networks such as Facebook illustrate the idea as well, with each person on the network representing a node. The edges or connections between these nodes are highly varied and unpredictable.
By contrast, conventional computers are designed to handle data stored in structured rows and columns. “Today’s systems are designed for computing problems where you typically step through your data in memory very systematically, one line after another,” says Bader.
Current techniques for improving performance, such as “pre-fetching” the next segment of data from disk, writing it into memory just before the processor actually needs it, were developed to make this sequential process go faster.
However, they’re ill-suited for graphical inference problems. The random nature of interconnections between city residents, businesses, and departments, for example, means that the “next data” needed isn’t likely to be as close in memory as the next row or column in a database.
The best way to handle graph data, says Singhal, is to put the whole graph in memory at once, and make all physical blocks of memory equally quick to access. Memory-Driven Computing makes that much more feasible.
The implications go far beyond more efficient construction zones. For example, a city can start with an understanding of what citizens value—things like lifestyle, open spaces, affordable housing and so on. Planners can then use a computer that holds many variables and data points in memory to test scenarios and see the larger effects of tactical decisions.
“If I ask a question about allowing a new high-rise to be built, or changing the zoning laws from a commercial zone to a residential zone, what would be the overall impact on the city?” Singhal asks. Today, he says, people make these decisions based on educated guesses, or simulations that account for only a few variables—limited as always by computing memory and time.
Memory-Driven Computing will allow analysts to consider exponentially more variables, delivering a broader and much more accurate and broader view of each decision’s implications.
Speech recognition
Computers as small as a smartphone do a decent job with speech recognition—in certain controlled circumstances. Voice assistants like Apple’s Siri and Microsoft’s Cortana claim to achieve 95 percent accuracy in recognizing individual words.
This works well for tasks like providing driver navigation, in part because the vocabulary involved is relatively small. Street names don’t change often, and linguistic complications like sarcasm don’t usually come into play.
This seemingly straightforward case masks a great deal of complexity that limits the practical value of speech recognition. Most speech recognition is achieved through so-called supervised learning, which exposes the system to millions of words and phrases along with their meanings so that the system can construct a model of how language works. The hope is that this model will then allow the system to successfully interpret utterances it’s never heard before.
The supervised learning to create the model is a computationally intensive process that can take six weeks. “To assemble phonemes into words, assess grammar, deal with ambiguity in language—it’s a huge training challenge,” Bresniker says.
As a result, these systems can’t currently keep up with news cycles, linguistic fads, and other fast-evolving trends.
To process language and determine meaning, computers convert words into mathematical expressions and apply a series of mathematical operations, checking different models to find the one that yields the most likely meaning.
The main computational task underlying these operations is matrix multiplication, says Natalia Vassilieva, a research manager at Labs. One matrix or sequence of numbers is multiplied by others to see which multipliers produce the most accurate output.
These matrices are much more predictable than the relationships in large graphs. It’s usually possible to anticipate the next set of data that a transformation requires, allowing the computer to access relevant areas of system memory ahead of time.
The bigger challenge lies in the communications overhead required to keep all the processors in the system busy, breaking utterances into tasks, distributing the work, and reassembling results.
The ultra-fast fabric that Labs is working on to interconnect memory nodes can perform this training much faster than existing technology. “We are hoping to take six weeks of training time down to six hours,” says Bresniker.
The result will be voice recognition technology that can rapidly learn new words, handle breaking news events involving previously unfamiliar people or terms, and parse the rapidly changing vocabulary of Internet memes.
Transportation systems
It’s happened to everyone: Your flight arrives on time, but has to sit on the tarmac because another plane hasn’t left the gate. Meanwhile, out the plane window you see adjacent gates sitting empty. Why is it so hard to shift the arrival one gate to the right?
“It’s not because people are stupid, it’s because we’re bound by computational models that grow complex very quickly as you add variables,” says Jaap Suermondt, vice president for HPE Software. Today’s transportation management systems just can’t change schedules on the fly. There are too many variables involved, given the interconnected nature of rail, trucking, and other transport systems.
There are many constraints in this kind of system. How many passengers can a plane carry? How much luggage? How much fuel is required, and what is the capacity and schedule of the refueling vehicles? What crew is available on the vehicle, on the ground, and at the terminals or gates?
Transportation systems have so many variables that conventional computing systems aren’t able to evaluate them at once. As a result, one system handles reservations. Another manages baggage handling. A third system processes gate and crew assignments.
If a single pool of memory held all the relevant data at the same time, transportation systems could be managed in an entirely different way. With a huge pool of non-volatile memory available, transportation companies and government agencies will be able to run what-if scenarios to identify the optimal response to common disruptions.
Because nonvolatile memory is, in theory, nearly limitless and requires no ongoing power consumption, the scenarios can sit in memory indefinitely. The system can pull out the appropriate, pre-computed solution in the event of a flight cancellation or a thunderstorm, managing all the disparate resources necessary to reroute passengers, flights, or cargo.
Even if there’s no exact match for the scenario at hand, Bresniker says, the pre-computed scenarios can still “prime the pump, giving hints as to the best solution. Then you can compute the exact answer in seconds instead of waiting 45 minutes to get a solution, while the problem creates cascading failures in other systems.”
Handling irregular events like this is a key step forward for logistics companies, which typically operate on thin margins. Bresniker says Memory-Driven systems can also help give passengers a more efficient and enjoyable experience.
“Irregular operations are just the first step in moving from independent and often antiquated systems, and have it all operate in real time,” he says.
Healthcare
Over the past decade, health data has gone digital: MRI images, genomic data, clinical trials, patient histories, and electronic health records of all sorts now reside in computing systems.
But we haven’t really taken advantage of all that data yet. “Even though healthcare is 20 percent of the economy, we’ve been using methods that can only look at a few thousand patients to decide what’s right for the average person,” Suermondt says. Today’s computers can’t run larger analyses efficiently enough.
Memory-Driven Computing would allow healthcare providers to look at data from every relevant patient, clinic, hospital, doctor, or disease, to see exactly what was done, what the result was, what worked, and what didn’t.
The shared memory pool allows computing systems to sift through this information fast enough for physicians to create a diagnosis and treatment plan for all patients—even those with complex symptoms—within hours or minutes of admission, rather than waiting weeks or months in difficult cases.
“When you’re talking a genome or large set of images, doing these comparisons is very laborious and memory intensive, even if the algorithms are straightforward,” Bresniker says.
Coming online
In November 2016, Labs announced it brought online the first fully functional hardware prototype of a Memory-Driven Computer. This major milestone in The Machine research project demonstrated that the team’s breakthroughs in photonic communications, non-volatile memory, systems architecture and new programming models could come together into a unified Memory-Driven Computing architecture. Working with this prototype, HPE will be able to evaluate, test and verify the key functional aspects of this new computer architecture and future system designs.
One key part of the ongoing research effort is making the architecture and the simulation tools available to the broader software community so that outside parties can design new applications.
“We tell development teams, ‘Start with this simulator, and eventually I’ll give you something ten times as big and fast,’” Bresniker says.
This kind of high-speed, high-capacity memory architecture opens up the possibility of dealing with other problems that have resisted computing until now. Examples of what Bresniker calls “real-world scale problems” include identifying malware in enterprise IT systems, optimizing traffic flows in real time, and analyzing national intelligence data.
Relationships in data at this scale are not only too complex for casual observation, but also for today’s memory-constrained computers. Removing those constraints creates the ability to examine gigantic volumes of data and address society-level problems.
And that, says Bresniker, is “how you get a city, economy or enterprise that can react in real time.”
